Local chat with Ollama and Cody
A few weeks ago I wrote a blog post on how you can use Cody's code completion features with local LLM models offline with Ollama. Users loved this feature and so at a recent hackathon our engineering team got together and expanded this functionality to Cody chat as well. Today, let's talk about Cody chat and how you can combine it with Ollama to have a fully offline AI-powered coding experience.
Using AI coding assistants is a great way to improve your development workflows. But they typically require access to the Internet as well as access to large language models like GPT or Claude. This is a problem for developers who work in air-gapped environments or places with limited Internet access. Additionally, accessing these LLMs typically has a cost associated with it. We are building Cody, an AI coding assistant that has a deep understanding of your entire codebase to help you write and understand code faster.
For developers that want to experiment with AI-powered coding assistants on their own hardware, Ollama provides a great solution. Ollama allows you to download and run various LLMs on your own computer and Cody can use these local models for code completion and now chat as well. In this article we'll take a look at how.
Note: This feature is experimental and only available to Cody Free and Pro users at this time.
Ollama - run LLMs locally
Ollama is a tool for running large language models (LLMs) locally. Ollama bundles model weights, configurations, and datasets into a unified package managed by a Modelfile.
Ollama supports many different models, including Code Llama, StarCoder, Gemma, and more. Ollama supports both general and special purpose models. Check out the full list here.
Getting started with Ollama
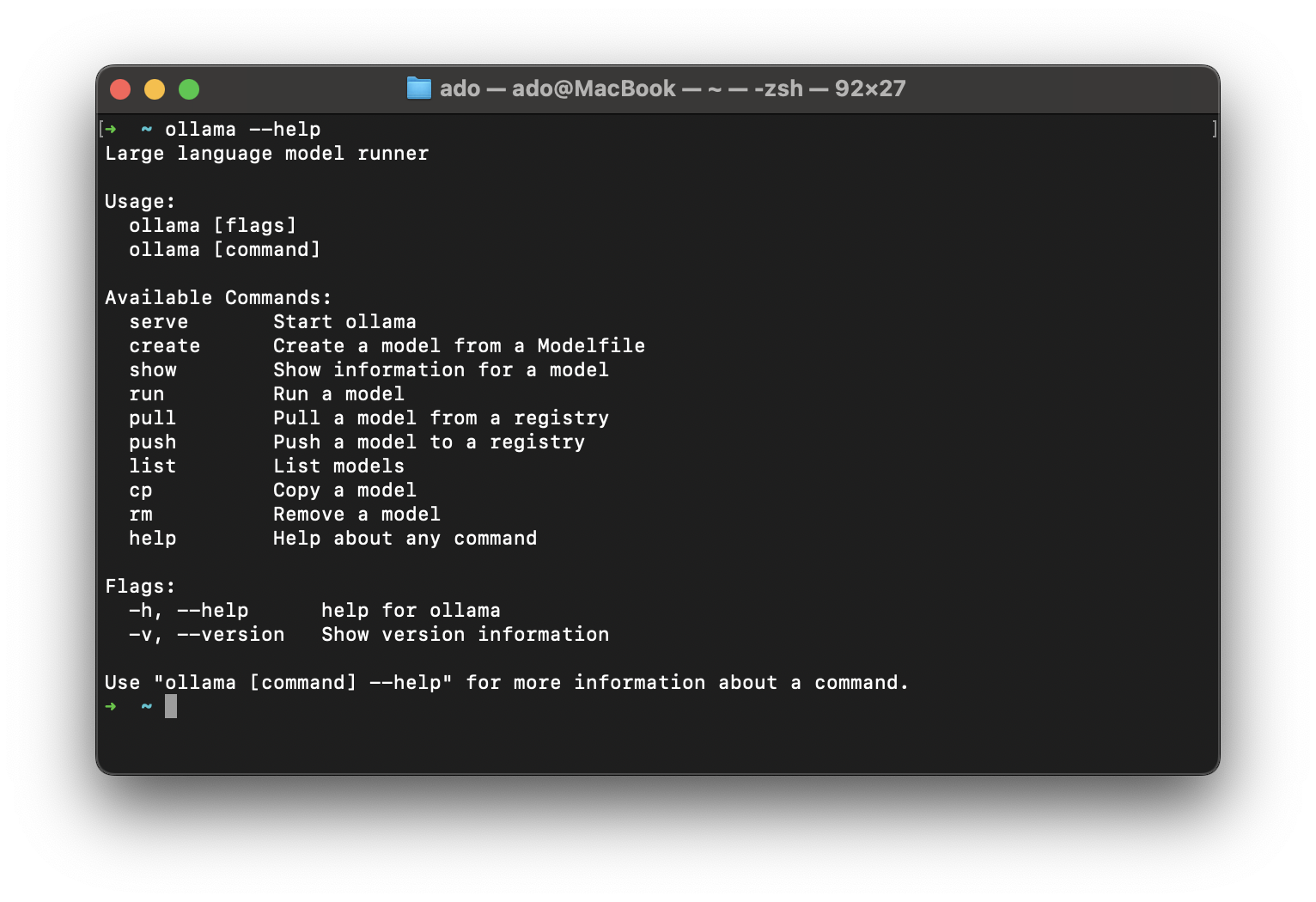
Ollama is a CLI tool that you can download and install for MacOS, Linux, and Windows. Head over to the download page and download the appropriate package for your operating system. Once you have downloaded and installed Ollama, verify that it is working by running the following command:
ollama --helpThis should output the following:
Downloading LLMs
Now you are ready to download and install a LLM. To download a model, you can use the following command:
ollama pull <model-name>For example, to download the mixtral model, you would run the following command:
ollama pull mixtralMany models offer multiple variations from parameter size, quantization, or intended interaction, and with Ollama you can download a specific version by providing the additional paramaters. For example:
ollama pull llama2:70bRunning the above command will pull the 70 billion paramater Llama 2 model, which is much larger than the default 7b model, both in terms of size and the hardware resources required to run it.
Important Note: Your ability to run a model is heavily dependent on your hardware. The larger the model, the more resources you will need to succesfully run it.
Running LLMs locally
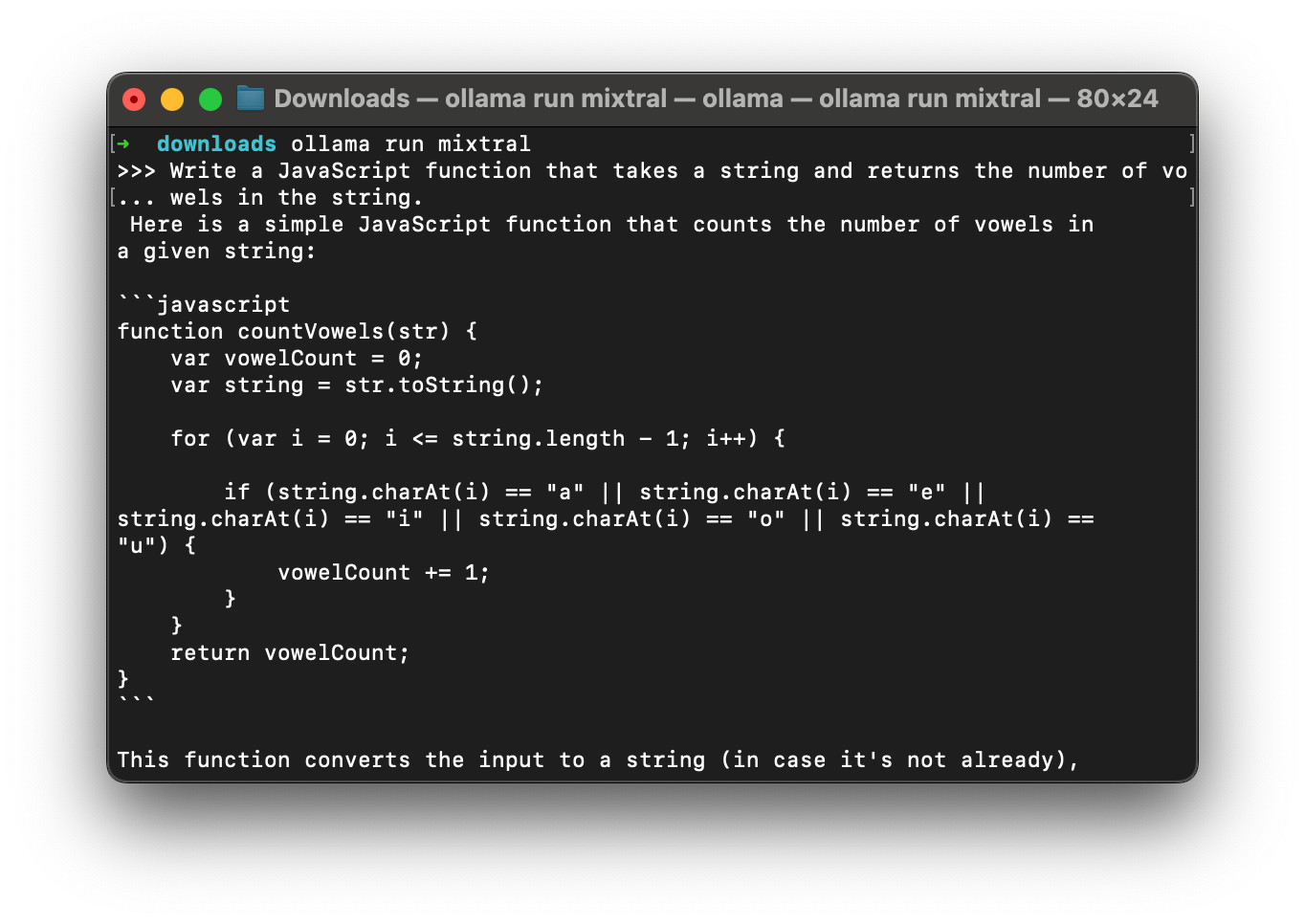
Once you have downloaded a model, you can run it locally by specifying the model name. For example, to run the mixtral model, you would run the following command:
ollama run mixtralBy default, Ollama will run the model directly in your terminal. Once the model is running, you can interact with it by typing in your prompt and pressing enter. For example, once the model is running in your terminal, you can type in the following prompt:
Write a JavaScript function that takes a string and returns the number of vowels in the string.And press enter. Ollama will respond with an output like this:
Ollama REST API
Ollama provides a REST API that you can use to interact with your downloaded models. By default the REST API for chat requests is available at http://localhost:11434/api/chat. The REST API exposes a number of additional endpoints for completions, managing models, and more. You can find more information about the REST API here.
To use the REST API, you make a POST request to the /api/chat endpoint with the following JSON payload:
{
"messages": [
{
"role" : "user",
"content": "Your initial message"
}
],
"model": "The model that you want to use",
"stream": false
}The messages value is an array containing the conversation with the LLM. The array acts as a sort of memory, so as new messages are added, the model can reference the previous messages to maintain the context of the conversation. The model field is the name of the model you want to use. There are additional parameters you can pass in such as stream, context, format, and others, but the only required parameters are the messages and model fields. In our example above, we set the stream value to false, which tells Ollama to return a single response object, rather than streaming the response as tokens become available.
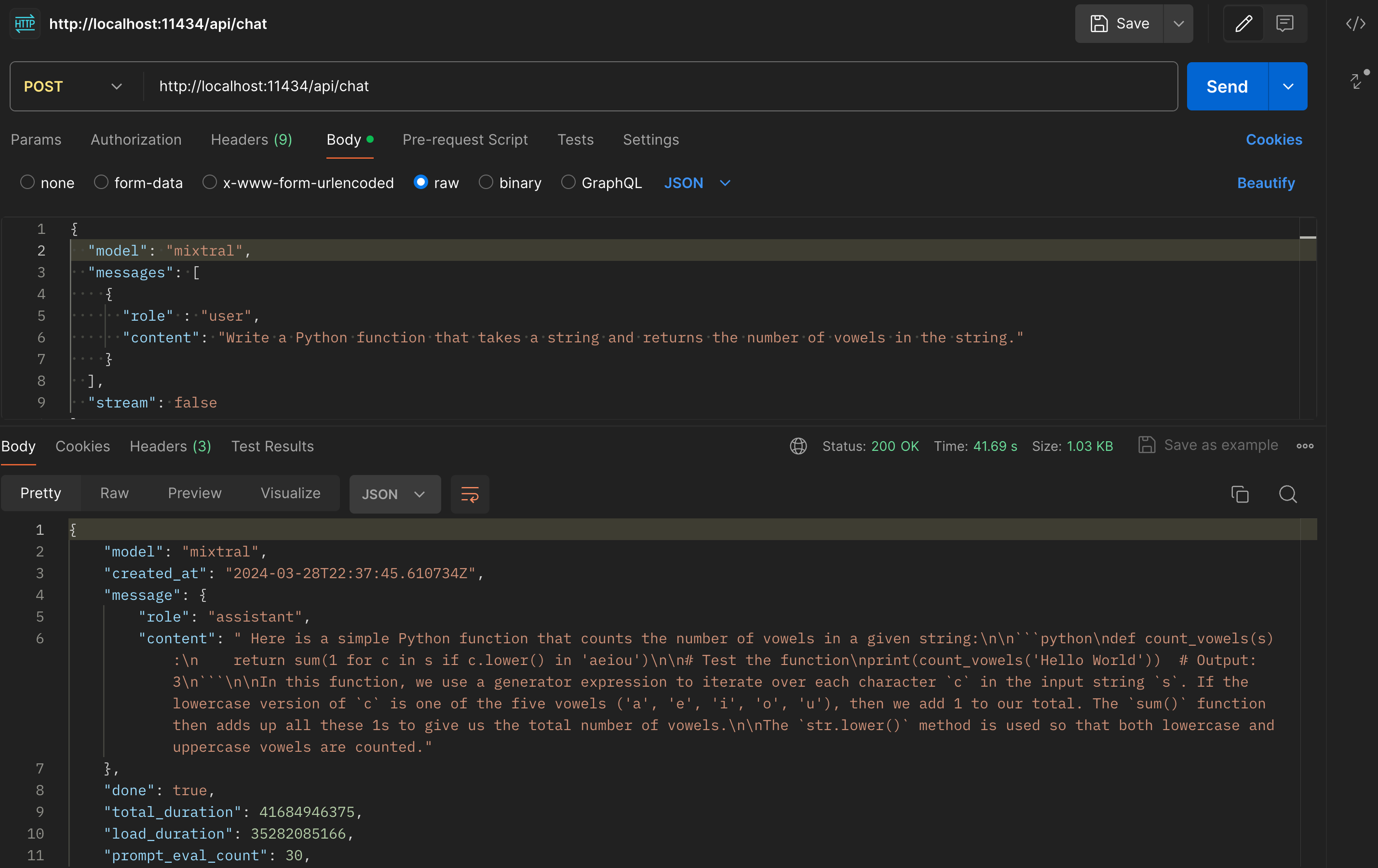
Let's try it out! Let's make a POST request to the /api/chat endpoint with the following JSON payload:
{
"model": "mixtral",
"messages": [
{
"role" : "user",
"content": "Write a Python function that takes a string and returns the number of vowels in the string."
}
],
"stream": false
}You can use a tool like Postman to make the request. Once you have the request set up, you can send it to the /api/chat endpoint and see the response.
Local chat with Ollama and Cody
Now that you have Ollama installed and running locally, you can use it with Cody to get local chat with any of the supported models. By default, Cody uses Anthropic's Claude 2 model for chat, but Cody Pro users have unlimited access to additional LLMs including GPT 3.5 Turbo, GPT 4 Turbo, Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus, and Mixtral 8X7B. Accessing these models requires an Internet connection.
You may be asking why you would want to run a local chat model with Cody instead of just making POST requests or building your own UI to interface with the exposed Ollama endpoints. The biggest benefit is that even with local models, you are able to leverage Cody's superior context fetching capabilities to get responses that are tailored to the codebase that you are working in rather than just getting general answers to your questions.
To enable local chat, you first need to install the Cody VS Code extension. Once you have the extension installed, you can configure it to display Ollama models for chat by following these steps:
- Navigate to your Visual Studio Code user settings by opening the command palette (⌘+shift+P) and typing
Preferences: Open User Settings (JSON). - Add the following property to
settings.jsondocument:"cody.experimental.ollamaChat": true - Restart Visual Studio Code.
Once you have restarted Visual Studio Code, you will have access to any downloaded Ollama model in your LLM selection dropdown in the Cody chat panel. To quickly open up the chat panel you can use the ⌥+L shortcut. Click on the LLM selection dropdown to see what is available. Local Ollama models will have a "by Ollama" designation.
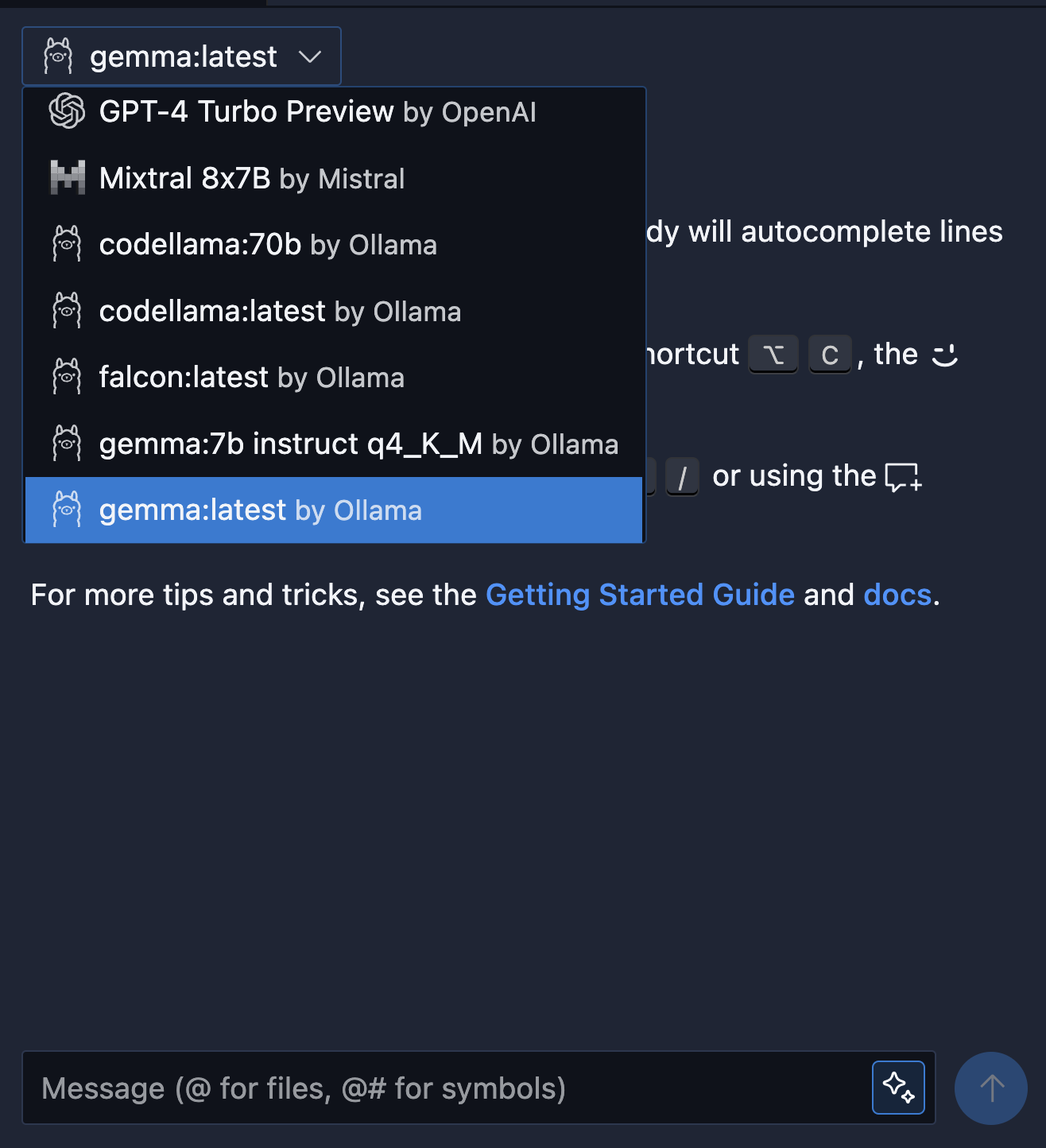
Do note that the dropdown will display all of the Ollama models you have downloaded, not just ones that are tuned for chat interactions. While you can use any of the models, the quality of responses may not be optimal if you are using a completion model for chat. I have found that using the llama2 and gemma:instruct models work really well for chat.
And with that, you are able to access any chat with Cody using any downloaded Ollama model. Happy chatting!
Conclusion
With Ollama and Cody, you can now have both local code completion and chat. This is a great way to improve your development workflow whether you're trying new LLMs or catching a flight and lacking Internet access. As mentioned in the intro to this post, local inference with Ollama for Cody is still experimental and we are working on improving the experience and bringing you more features.
If you have any questions or feedback, please let us know by opening an issue on our GitHub repository, join our Discord community, and if you haven't already, give Cody a try yourself!